5.5 Hochdimensionale Visualisierung



5.5 Hochdimensionale Visualisierung |
|
Alle bisher angesprochenen Methoden zur Visualisierung beschränkten sich auf die Darstellung von Daten, die von ein oder zwei Variablen abhängig sind. Diese Grenze ist durch die Beschränkung der normalen Darstellung auf drei Dimensionen gegeben. Es gibt zwei mögliche Erweiterungen, um diese Grenze der drei Dimensionen zu überschreiten. Dies wäre zum ersten die Verwendung von Farbe als 4. Dimension und der Zeit als 5. Dimension. Die Darstellung von vier Dimensionen ist mit etwas Übung gut nutzbar. Aber spätestens bei der Verwendung der Zeit zur Visualisierung der 5. Dimension wird es für den Betrachter ungewohnt und die Darstellung schwer interpretierbar. Wenn nur vier oder fünf Dimensionen dargestellt werden müssen, sollten beide Methoden in Betracht gezogen werden. Doch ein Nachteil bleibt: bei fünf Dimensionen ist wiederum Schluß. Beide Varianten lassen sich nicht beliebig auf höhere Dimensionen erweitern.
Zur Visualisierung hochdimensionaler Daten muß ein Weg gefunden werden, wie diese Daten auf weniger Dimensionen herunter skaliert oder umgerechnet werden können. Es muß versucht werden, die Datenpunkte aus einer hohen Dimension so in einer niedrigen Dimension abzubilden, daß beide Darstellungen ähnlich zueinander sind. Als Ähnlichkeitsmaß bietet sich die Distanz zwischen den Datenpunkten in beiden Bereichen an. Die Aufgabe besteht darin, eine Abbildung zu finden, bei der die Abstände zwischen den Datenpunkten im hochdimensionalen Raum mit denen im niedrigdimensionalen Raum korrespondieren. Die Nahordnung der Datenpunkte soll erhalten bleiben. In der Literatur zur Mustererkennung und Klassifikation (u.a. [DH73], S.243-246 und [Rip96], S.305-311) werden solche Methoden als mehrdimensionale Skalierung (multidimensional scaling) bezeichnet.
Die Distanzen zwischen verschiedenen Datenpunkten können einmal echte Abstände sein oder einen Ersatz für den Abstand darstellen, wenn direkte Werte nicht berechenbar sind. Beide Arten von Abständen werden meist unter dem Begriff Ungleichheit (dissimilarities) zusammengefaßt. Diese Ungleichheiten müssen die Dreiecksungleichung nicht zwingend erfüllen. Im folgenden soll nur auf echte Abstände eingegangen werden, für die als Abstandsmaß der euklidische Abstand verwendet wird. In der Literatur (z.B. [Rip96] und [CC94]) finden sich weitere Abstandsmaße, die bei Daten zur Anwendung kommen, bei denen es nur auf die Ordnung der Abstände untereinander ankommt und nicht auf den absoluten Wert des Abstandes.
Die folgenden Erläuterungen der mehrdimensionalen Skalierung orientieren sich an [DH73], ab S.243. Als Bezeichnungen werden verwendet:
![]() (5-2)
(5-2)
Es müssen die Bildpunkte y1,...,yn gefunden werden, für welche die Abstände dij so nah wie möglich an den entsprechenden Abständen _ij der originalen Datenpunkte x1,...,xn sind. Nur selten ist es möglich, Bildpunkte zu finden, so daß dij = _ij für alle i und j gilt. Deshalb muß ein Kriterium definiert werden, das angibt, wie gut eine Konfiguration von Bildpunkten im Vergleich zu anderen Konfigurationen ist. Die Summe der Fehlerquadrate ist Grundlage der am häufigsten benutzten Kriterien.
In [DH73] werden drei Varianten der Funktionen für die Bewertung des Fehlers bei der mehrdimensionalen Skalierung (Summe der Fehlerquadrate) vorgeschlagen (linke Spalte: Kriterien; rechte Spalte: 1. Ableitung der entsprechenden Funktion):
Kriterium Jee in Gleichung 5-3 betont die größeren Fehler, egal ob die Abstände _ij groß oder klein sind. Kriterium Jff in Gleichung 5-4 hebt die größeren relativen Fehler hervor, egal ob der Betrag des Fehlers groß oder klein ist. Kriterium Jef in Gleichung 5-5 bildet einen vernünftigen Kompromiß zwischen den beiden ersten Kriterien, indem es das größte Produkt aus Fehler und relativem Fehler betont.
Da sich die Ableitungen der Kriterien einfach berechnen lassen, siehe rechte Spalte der Gleichungen 5-3, 5-4 und 5-5, kann eines der vielen bekannten Gradientenverfahren zur Ermittlung einer optimalen Konfiguration von Bildpunkten verwendet werden.
Eine der bekanntesten Methoden der mehrdimensionalen Skalierung ist das Sammon-Mapping [Sam69]. Sammon verwendete das Kriterium der Gleichung 5-5 und ein Verfahren des steilsten Abstiegs (diagonales Newtonverfahren). In [Rip96] wurde berichtet, daß das von Sammon benutzte Optimierungsverfahren nicht immer konvergiert. Oftmals mußte eine wesentlich kleinere Schrittweite verwendet werden, als von Sammon angegeben, damit das Verfahren nicht divergiert.
Als Optimierungsverfahren, das den Gradienten verwendet und robust ist, wird das Rprop-Verfahren [RB93] vorgeschlagen und im folgenden standardmäßig eingesetzt. Rprop verwendet für die Generierung eines neuen Punktes nur die Richtung des Gradienten und nicht den Betrag. Die Schrittweitensteuerung von Rprop wird vom Wechsel des Vorzeichens des Gradienten gesteuert. Rprop hat sich im Bereich Neuronaler Netze in den letzten Jahren bewährt und wird dort oft eingesetzt.
Die Ausgangskonfiguration von Bildpunkten für die mehrdimensionale Skalierung kann zufällig erstellt werden. Eine deutliche Verbesserung der Suche nach einer optimalen Konfiguration sowie eine Beschleunigung der Optimierung können durch eine sinnvolle Auswahl der Anfangskonfiguration erreicht werden. Die principal component analysis (PCA) ist eine dafür geeignete Methode, die durch vorhandene Programmierungswerkzeuge oft bereitgestellt wird.
Wofür läßt sich die mehrdimensionale Skalierung im Bereich der Visualisierung Evolutionärer Algorithmen einsetzen? Die Anwendung ist überall dort interessant, wo viele hochdimensionale Datenpunkte in ihrer Beziehung zueinander dargestellt werden sollen. Die folgenden Beispiele geben eine Auswahl:
Mit der Darstellung der Individuen der Population erhält man ein Bild, wie die Individuen im Suchraum verteilt sind bzw. wie der verwendete Algorithmus den Suchraum durchmustert. Damit ist auch zu erkennen, ob die Individuen alle in einem Bereich liegen, oder ob sie weiter voneinander entfernt sind.
Die Darstellung mehrkriterieller Zielfunktionswerte ermöglicht deren optische Bewertung. Bis zu drei Dimensionen geht dies noch direkt mit den Methoden, die von Fonseca in verschiedenen Arbeiten (u.a. [Fon95] und [FF96]) vorgestellt wurden. Bei vier und mehr Kriterien bietet sich die mehrdimensionale Skalierung an.
In Abbildung 5-18 sind zwei Beispiele der mehrdimensionalen Skalierung für die besten Individuen eines Laufs gegeben. In beiden Beispielen ist jeder der Datenpunkte mit der Nummer der Generation beschriftet, aus der das entsprechende Individuum stammt.
Abbildung 5-18: Mehrdimensionale Skalierung der besten Individuen eines Laufs; links: Rosenbrock's Funktion 2, rechts: Gleichstrom-Steller Nr.45 (siehe Abschnitt 7.2, ab S.)
Der Weg des besten Individuums eines Laufs für Rosenbrock's Funktion 2 in zehn Dimensionen (zehn Variablen) ist in Abbildung 5-18, links, dargestellt. Die zweidimensionale Darstellung ergibt eine stark gekrümmte Linie, ähnlich einer Banane (Rosenbrock's Funktion wird oft als Bananenfunktion bezeichnet). Die Darstellung zeigt damit dieselbe Charakteristik für diese Funktion, die schon aus der direkten zweidimensionalen Darstellung bekannt ist, siehe Abbildung 5-15.
Abbildung 5-18, rechts, zeigt den Weg des besten Individuums für eine der Optimierungen aus dem Anwendungskapitel, den Gleichstrom-Steller aus Abschnitt 7.2. Die Individuen haben jeweils neun Variablen. Die zweidimensionale Darstellung unterscheidet sich deutlich von der für Rosenbrock's Funktion. Es ergibt sich keine Linie durch den Suchraum, dem die Individuen während des Laufs folgen. Vielmehr läßt sich erkennen, daß in den ersten Generationen die Individuen in einem Bereich liegen. Das Individuum von Generation 10 ist dagegen weit von den Individuen der vorherigen Generationen entfernt. Die Individuen aller nachfolgenden Generationen finden sich zwischen diesen bisherigen Extremwerten in einem relativ kleinen Gebiet.
Abbildung 5-19: Mehrdimensionale Skalierung mehrkriterieller Zielfunktionswerte
Abbildung 5-19 zeigt zwei Beispiele der mehrdimensionalen Skalierung für mehrkriterielle Zielfunktionswerte der besten Individuen eines Laufs. Genau wie in Abbildung 5-18 ist in beiden Beispielen jeder der Datenpunkte mit der Nummer der Generation beschriftet, aus der das entsprechende Individuum stammt. Jeder Zielfunktionswert besteht aus sechs Kriterien.
In Abbildung 5-19, links, ist zu erkennen, wie es nach anfänglichen langsamen Veränderungen zwischen Generation 20 und 25 zu einem Sprung kommt. Danach findet eine kontinuierliche Verbesserung statt, die in etwa einer Linie folgt.
Deutlich anders ist die Darstellung in Abbildung 5-19, rechts, die mit Abbildung 5-18, rechts, korrespondiert. Die Zielfunktionswerte von Generation 1 liegen weit entfernt von denen der Generationen 3 bis 10. Alle folgenden Generationen liegen wiederum weit entfernt von den bisherigen Werten. Ähnlich zu Abbildung 5-18, rechts, liegen diese Werte wieder in einem sehr kleinen Bereich. Im Vergleich der mehrdimensionalen Skalierung für Individuen und Zielfunktionswerte für dieses Beispiel zeigen sich einerseits weite Übereinstimmungen, andererseits auch Unterschiede. Ähnlich ist die Clusterung zwischen Beginn und Ende des Laufs. Anders ist die direkte Clusterung zu Beginn des Laufs. Die Individuen von Generation 1, 3 und 5 liegen dicht beieinander und 10 weit entfernt, Abbildung 5-18, rechts. Bei den Zielfunktionswerten ist der Wert von Generation 1 weit von denen der Generationen 3, 5 und 10 entfernt, Abbildung 5-19, rechts. Durch diese Darstellung der mehrdimensionalen Skalierung können damit weitere Informationen zu einem Problem erarbeitet werden, die sonst kaum zugänglich sind.
Die Analyse von Daten durch die mehrdimensionale Skalierung kann auf den Vergleich der Daten von mehreren Läufen ausgedehnt werden. In Abbildung 5-20 ist dafür ein Beispiel gegeben. Die Daten stammen wiederum von den Optimierungen des Gleichstrom-Stellers, siehe Abschnitt 7.2, ab S.. Die Grafiken zeigen gleichzeitig die Individuen bzw. Zielfunktionswerte von zwei Läufen. Jeder Datenpunkt ist mit der Nummer des Laufs (1_, 2_)und der jeweiligen Generation beschriftet.
Abbildung 5-20: Vergleich der besten Individuen und der mehrkriteriellen Zielfunktionswerte zweier Läufe durch mehrdimensionale Skalierung
Die Individuen beider Läufe liegen für die ersten Generationen in demselben kleinen Bereich, siehe Abbildung 5-20, links. Ab etwa Generation 20 entfernen sich die Individuen vom Startbereich. Dabei folgen die Individuen in den beiden Läufen verschiedenen Wegen. Am Ende der Läufe sind die Individuen weit voneinander entfernt. Bei den Zielfunktionswerten ist das Bild etwas anders. In den ersten Generationen sind die Datenpunkte in einem weiten Bereich verteilt. Dann bewegen sich die Datenpunkte in denselben Bereich hinein, wobei sie aber unterschiedlichen und voneinander getrennten Linien folgen. Besonders bei den Zielfunktionswerten des ersten Laufs ist dies gut zu erkennen.
Durch diese Art des Vergleich verschiedener Läufe können detaillierte Informationen über den ,,Weg" der Individuen durch den Suchraum bzw. die Relation der mehrkriteriellen Zielfunktionswerte zueinander erarbeitet werden. Damit eröffnet die mehrdimensionale Skalierung einen neuen Bereich der Visualisierung von Daten, der mit den bisher vorgestellten Verfahren so nicht möglich war.
Erste Arbeiten zur Anwendung des Sammon-Mapping auf dem Gebiet der Evolutionären Algorithmen wurden in [DCW96] und [Col97a] berichtet.
In [DCW96] wurde Sammon-Mapping direkt verwendet. In der Arbeit wird allerdings nur auf die Verwendung von Variablen in einer binären Repräsentation eingegangen. Weiterhin wird in der Arbeit davon ausgegangen, daß es möglich ist, zu Beginn einer Optimierung ein Mapping für alle möglichen Individuen aufzustellen und die entsprechenden Positionen dieser Individuen im niedrigdimensionalen Raum in einer Tabelle abzulegen. Dadurch muß während eines Laufs nur eine Referenz in einer Tabelle gesucht und keine Optimierung der Abstände durchgeführt werden.
Von Collins wurde in [Col97a] das `Genotype-Space Mapping' präsentiert. Dieses ermöglicht die analytische Konstruktion eines Mapping aus einem hochdimensionalen in einen niedrigdimensionalen Raum, ähnlich dem Sammon-Mapping. An einigen Beispielen für binäre Variablen geringer Länge wurden Vergleiche zum Sammon-Mapping durchgeführt. Im Ergebnis war das `Genotype-Space Mapping' im Fehler zwar nicht ganz so gut wie ein konvergiertes Sammon-Mapping, dafür läßt sich das `Genotype-Space Mapping', zumindest für Individuen mit wenigen Variablen, direkt und schnell berechnen. Collins demonstrierte außerdem, wie sich für Variablen einer höheren Basis ein `Genotype-Space Mapping' aufstellen läßt.
Für Probleme mit wenigen binären Variablen sind beide Methoden sehr gut geeignet und während eines Laufs sehr schnell. Speziell die Art der Ergebnisdarstellung in [DCW96] und die Anzeige der nächsten Nachbarn sind für die praktische Anwendung gut geeignet. Die Skalierbarkeit beider Methoden ist dagegen schlecht. Schon für Probleme mit 30 und mehr Variablen ist die vorhergehende Berechnung aller Mapping-Positionen und deren Speicherung nicht mehr praktisch anwendbar. Bei einer reellen Repräsentation der Variablen wird es noch schwieriger, da vorher eine Diskretisierung der Domain der Variablen durchgeführt werden muß und dadurch die Dimension des Problems weiter ansteigt.
Für die Darstellung der Positionen von Individuen im Suchraum im Verlauf einer Optimierung stellt sich ein Problem: wird in jeder Generation ein selbständiges Sammon-Mapping durchgeführt, ist keine Vergleichbarkeit der Abbildungen zwischen den Generationen gegeben. Selbst wenn sich die Position nur eines Individuums ändert, kann die Darstellung des resultierenden Sammon-Mapping deutlich anders sein.
Für die Lösung bzw. Umgehung dieses Problems sind zwei Varianten denkbar, je nach beabsichtigter Anwendung. Bei einer direkten Beobachtung der Optimierung wird jeweils das Ergebnis des vorherigen Sammon-Mapping als Startpunkt verwendet und die Individuen der aktuellen Generation werden als zusätzliche Punkte in die Optimierung einbezogen. Dargestellt werden dann allerdings nur die Individuen der aktuellen Population. Bei einer nachträglichen Betrachtung der Optimierungsergebnisse kann ein Sammon-Mapping über alle Individuen aller darzustellenden Generationen durchgeführt werden. Bei der Darstellung der Daten einer oder mehrerer Generationen werden dann immer nur die Daten der jeweiligen Generationen gezeigt. Dies kann zwar auch einen sehr hohen Rechenaufwand für das Sammon-Mapping zur Folge haben, dürfte aber, besonders bei der Anwendung auf reale Probleme, immer noch deutlich geringer sein, als ein Sammon-Mapping für alle möglichen Individuen. Es wird wirklich nur für diejenigen Individuen ein Mapping durchgeführt, die dann auch dargestellt werden sollen.

Diese Dokument ist Teil der Dissertation von Hartmut Pohlheim
"Entwicklung und systemtechnische Anwendung Evolutionärer Algorithmen".
This document is part of the .
The is not free.
© Hartmut Pohlheim, All Rights Reserved,
(hartmut@pohlheim.com).
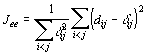
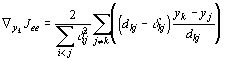 (
(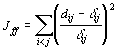
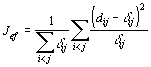
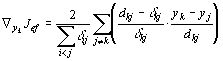 (
(